| 新着ソフトレビュー | 2014.11.06 |
| Vectorトップ > ライブラリ > Dyngrep |
|
|
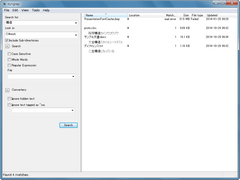
Microsoft Office文書やPDF文書などにも対応した、シンプルな文字列検索ソフト |
|
| ■Windows 7/Vista/XP ■その他 | ||
|
|
会社情報 | インフォメーション | はじめて利用される方へ | プライバシーポリシー | 免責事項
個人情報保護方針 | 利用者情報の外部送信について
(c) Vector HOLDINGS Inc.All Rights Reserved.
個人情報保護方針 | 利用者情報の外部送信について
(c) Vector HOLDINGS Inc.All Rights Reserved.